
Introduction
Hey, I’m Jake, and this is my blog. Previously, it was more focused on Game Development topics, but as I am moving into more cloud-native roles, I am shifting the focus. I plan to write more posts dealing with the various areas of AWS and hopefully explain them in a way that will be more helpful than just a vague metaphor, but not go so deep that someone tunes out.
This first post in “Adventures In Cloud” is meant to help people who are new to cloud computing get a handle on what it is, why it matters, when to use various services, what they can do with those services at a high level, and how they can get started building in AWS.
I say cloud, but as I am twice certified on AWS (SA SAA/Pro), most of the topics I discuss will be AWS-focused—many of them apply to other clouds. AWS doesn’t have a monopoly on the idea of compute as a service or virtual private clouds (VPCs)—many of the things I discuss will have a 1:1 match in other providers such as Azure and GCP.
I’m writing this post because I believe that having more resources to help explain these topics can only help people get into this field, and that even though there is a ton of quality content written by folks a lot smarter than me, sometimes you need to have something explained from different perspectives for it to click. I hope that this post helps it click for you.
What is Cloud Computing, and why would I want to use it?
Cloud Computing, simply put, is running your software or business processes on underlying hardware you don’t have to think about. There is more to it, but that is the most basic idea around the cloud. The original value proposition of cloud computing is pretty easy to understand. Back before providers like AWS existed, companies looking to launch products or services requiring their own servers had to buy them.
This came with a bunch of downsides – cost, delay in setup, teams needed to install and manage the hardware, ongoing physical operations costs, and the risk that you either bought too much or too little compute. If you bought a server that was too big and your business or idea never took off, you are stuck holding the bag with a powerful server that is just sitting idle, wasting power and money. If you under-provisioned and needed to scale, it could take weeks to get new hardware in place and running.
So Cloud comes along (Someone at AWS had the idea that “hey, we use these services internally… what if we sold them?) and this now allows businesses and hobbyists (who were often priced out to begin with) to provision servers, on demand, and pay only for the servers they were using. It allowed people to scale up and down in minutes instead of weeks/months, and you pay a very small fraction of the underlying hardware cost on an hourly basis.
Aside: Technically, compute as a service wasn’t the first product AWS rolled out with – that honor belongs to SQS or the *simple queue service* which does what the name implies – provides a simple way for you to decouple requests coming in from the server they are going to, allowing for much better scaling and performance.
Today, AWS (and the other providers) offer *hundreds* of services to handle pretty much every possible need you or your project might require. Typically, in the cloud, you are paying for tradeoffs and convenience. Regardless, all of the various cloud providers will have services that allow you to provision and manage compute, storage, networking, security, monitoring, containerization, etc.
Everything in IT is a tradeoff, and cloud is no exception. You are typically trading cost for convenience. For example, most cloud providers offer their services as “managed services” – meaning they handle the underlying networking, hardware, and infra. level security, and you simply consume what you need from that service. RDS, or the Relational Database Service, is a great example of this. RDS lets you spin up, scale, and manage databases of various flavors easily in the cloud. You provision RDS, launch it into a Virtual Private Cloud you control, and are given an endpoint you connect to. The actual server running the database isn’t something you see, manage, or care about. On the flip side, nothing is stopping you from spinning up an EC2 Instance (EC2 is the AWS flavor of virtual machine) and installing a DB onto it. The tradeoff is that while potentially cheaper for a single DB, you are now responsible for managing, patching, updating, scaling, etc.
The other big thing that providers like AWS give you, assuming you are ok playing in their garden (vendor lock is another topic for another day), is seamless integration with other cloud services. For instance, you can chain together a series of services to provide functionality that would otherwise be very expensive to build out yourself. You could upload a file to S3 (simple storage service), have that file automatically be scanned for PII (sensitive information) with Macie, and if such information is found, trigger Lambda (‘serverless compute’ – I’ll get to that) and have the data removed before using SNS (simple notification service) to alert someone that a non-compliant file was uploaded. That is a simple, fairly arbitrary example – but take a second and think about a pipeline/set of processes YOU would want to be able to kick off.
Some things are worth the cost – maybe you have a smaller team and don’t have the resources to create something that AWS provides as a turn-key solution. Others can be quite expensive and need to be carefully considered to see if the benefit is worth the cost. While I am a huge fan of AWS and cloud computing in general (and despite what they want you to pick as answers on the certifications), sometimes NOT going with a cloud option for a given service is the right choice. It all depends.
Let’s talk structure – a 10000 foot view
“Ok, great,” you say, “but… that all seems pretty abstract.”
You’re not wrong. A lot of concepts and services *are* literal abstractions. But, that doesn’t do you, the reader, much good – so let’s visualize how all these pieces fit together and what a general AWS setup looks like.
So – AWS (and other clouds) work like this at a high level
Regions – Areas of the globe are split up into Regions. For instance, the US has four public regions, and two regions specifically for government services (GovCloud) – you can see the current regions for a given country HERE but the TLDR at least for the US there is us-east-1 (VA), us-east-2 (OH), us west-1 (OR), and use-west-2 (CA). The image below is just to help visualize this – each of those dots is a region, which is simply a “distinct, isolated geographic region/slice in a given area”. Not every Region offers every service, but they all pretty much have the ones you would expect. us-east-1 is the oldest, and typically has the newest toys, but in general, you are free to take your pick. Picking a region closest to your end users will, however, typically provide the best experience out of the box.
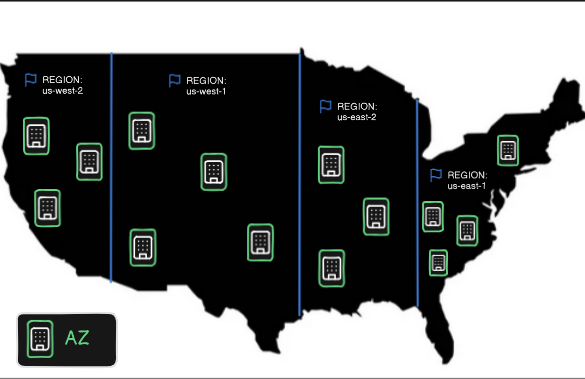
Availability Zones (AZs) – In each Region, you will find three or more entities called “Availability Zones” – these are each physical data centers located in a spread manner across a single region. Each AZ has its own dedicated hardware, networking, security, and other infrastructure needed to run the various AWS services you, as the user of these services, want to use. The reason each region has multiple AZs is for what is called HA and DR, or high availability and disaster recovery.
As I said, each AZ is a physical location – a real building (or campus) – if a single AZ is impacted by something like a natural disaster, a missile strike (unlikely but you never know), or a band of marauding Goombas – having your services placed in multiple availability zones (an extremely common practice) allows things to keep running as normal even if a single data center goes down. Some services are single AZ only, and that , like everything else, is a tradeoff. Some workloads benefit from having extremely close physical proximity to other machines they are using (processing speed in a cluster, enhanced networking, etc), but the tradeoff is, if that AZ goes down, you may lose your data.
Edge Locations and Local Zones – Edge Locations and Local Zones are both things that bring AWS even closer to the end user. Edge Locations are typically used with caching solutions (CloudFront in the case of AWS) while Local Zones extend part of the capabilities of a full AZ closer to end users, typically cities. When you get started with cloud computing, the Regional and AZ level is typically what you will be focused on.

There are some other things if you pursue this chain of nesting dolls far enough like AWS Outposts, but frankly, if you need to work at that level, you will know.
So, quick recap – AWS splits up geographical areas into Regions. Each Region consists of 3+ AZs. Each AZ is its own physical data center, housing the hardware that powers the services you’ll use. Edge Locations and Local Zones bring content caching and compute even closer to end users.
“Ok, great,” you say, “but… that all still seems pretty abstract,” you say.
You’re still not wrong. Bear with me.
*Inhales*
Ok, so you have picked a primary region and you are ready to spin up a bunch of virtual machines and take over the world. Not so fast. First, you have to provision a Virtual Private Cloud (VPC). A VPC is a logical resource – it is a conceptual “space” you provision across multiple availability zones in a region (though in many cases, you interact with it as if it were in a single location). Inside your VPC, you provision subnets. Subnets are isolated blocks that let you launch the actual services into, like EC2, RDS, etc. I think it might be helpful to add some visuals though, so let’s do that.
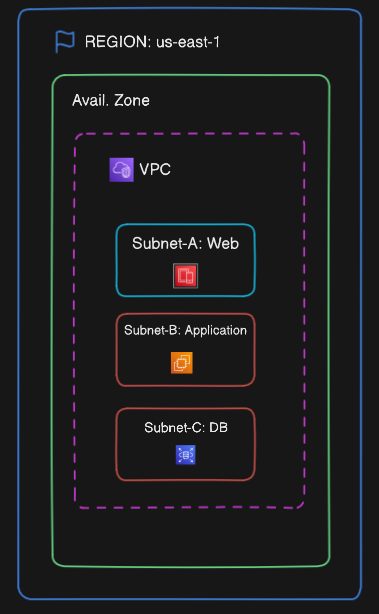
To start with, here is a diagram of a VPC with a single subnet inside a single AZ – this is 100% a setup you can do, and while not recommended for anything that needs to scale or be resilient, it’s a super easy setup to get started with both conceptually and inside AWS.
Here is a more typical setup – just so you can see how it works outside of a super basic example. In this case, you’ve got one Region (us-east-1) with three Availability Zones. Your VPC spans across all of them, and you’ve carved out three subnets in each one (this is a common pattern for a “three-tiered application”). If one AZ goes down, your app can keep chugging along in the others. AWS services like load balancers and auto scaling groups can use this structure to intelligently spread traffic and recover from failures.
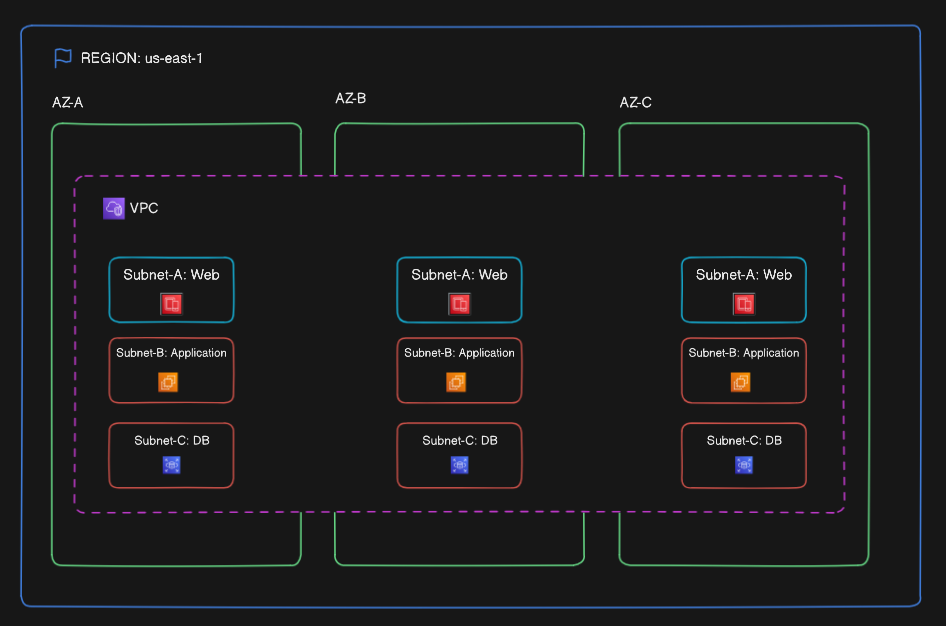
I am choosing to avoid overloading the diagram above, but in case you know enough to ask, “Wait a sec, where is the Internet Gateway?” just know that I am leaving that out for now on purpose.
By now, you should have a pretty solid idea of what cloud computing is, why you’d use a cloud provider, how AWS structures its infrastructure layers, and what high availability means at a basic level.
For the sharp-eyed among you, you may have noticed I mentioned serverless earlier. I’ll cover that more deeply in a future post, but for now, just know that serverless services are abstracted even further — you don’t manage virtual machines at all. You just pay to use them, and AWS handles the rest behind the scenes.
I bring this up now because most serverless services don’t live inside your VPC — instead, AWS runs them inside a VPC they manage, and your stuff connects to them as needed. That’s an important distinction, especially when you start thinking about access controls and private networking later on. Speaking of VPCs – let’s cover the basics of networking inside AWS next to help build a foundation moving forward.
Networking
Networking is crucial to most aspects of AWS. Traffic from the outside needs a way in. Things on the inside need a way out. Controlling that is critical. Below is a brief overview of the core networking concepts you should familiarize yourself with. This section isn’t very icon-heavy, as while icons do exist for each piece, these topics all holistically fit together as part of a greater whole.
VPCs – Virtual Private Clouds are an absolutely critical, core, foundational concept when it comes to networking in AWS. I mentioned this a bit earlier in my overview section, but let’s dig a little bit deeper here. You provision a VPC inside an account. This VPC is the top-level container for all your networking and resources that you will have in your account.
You get a default VPC out of the gate, but typically you should consider deleting it and creating one specific to your needs. You can learn more about how VPCs work HERE – and I highly suggest you do. I also rec you Google for “AWS VPC Diagram” to see a ton of great visual examples of this and the other topics in this section.
Subnets – Subnets are a way to split up your VPC into smaller, isolated chunks. If your VPC is like a private, undeveloped plot of land, a subnet is a plot for specific buildings. Subnets come in two flavors – private and public. By default, all subnets are private (unless you launch them into the default VPC) until you provide a way for traffic to get from the subnets to the outside world. A large number of services you will use in AWS require subnets to be in place – EC2, RDS, and ELBs, to name a few.
To continue the plot of land analogy, public subnets are like a part of your property you invite people onto, maybe for a cookout, and they can consume the things in that area – like the food on the table. Private subnets are like locked sheds somewhere else on your property that only you know about. A common pattern is to launch your public-facing services (like a web server) into a public subnet, and have your application tier and database in separate, private subnets. You control access to subnets with things called NACLS and Security Groups, which I will dive into shortly. You define how traffic can get to your subnets with Route Tables and Routes.
Route Tables – Route Tables are how you associate Routes with resources. Routing is a complex subject with a ton of nuance and gotchas, and I highly suggest you take the time to read through the docs to get a better idea of how this all works, but without a route table, traffic isn’t getting to your resources.
Internet Gateways – Internet Gateways, or IGs, are how traffic flows in and out of your VPC. It acts as the public entry and exit point for internet-bound traffic to/from your VPC – a gateway to the internet if you will. Without an IG, even if you have a route table set up correctly, nothing is getting into your VPC. Every VPC MUST have an IG if you intend for public traffic to interact in any way with your resources.
Security Groups – Security Groups (SGs) are stateful controls – this means that if traffic can come in, it can go out. Typically, you assign SGs to resources so they can easily communicate even if they are in different subnets. For instance, you might (and often will) have a SG for a group of EC2 instances that says “Anything that has this SG can talk to these EC2s” and then assign your Database to have a matching SG. This allows communication without having to specify each direction/side of the relationship. They don’t control where traffic goes — only whether it’s allowed to communicate once it arrives.
NACLs – (Network Access Control Lists) are *stateless* firewalls – Unlike security groups, they are controls that require you to not only specify if traffic can go in, but also if it can go out. You must define the relationship in both directions, both for incoming and outgoing traffic. They are often used in combination with security groups to control traffic inside your VPC and to lock down critical resources.
NAT Instances/Gateways – NAT, or Network Address Translation, is the process of modifying the IP address from incoming traffic to make sure it gets correctly routed to the corresponding resource. An analogy would be a mailbox in an apartment complex – NAT is what would allow letters addressed to you (and your responses) to get to where they are supposed to go, even though there are many potential mailboxes in the apartment itself.
NAT Instances and Gateways are a way for resources in your private subnets with IPv4 addressing to reach out to the internet, but not allow outside traffic in. This is useful if you have an instance in a private subnet that needs to get updates from an external server, but you don’t want any outside calls reaching back to initiate contact. Since resources in a private subnet by definition, have no way to communicate with the internet. A NAT instance/gateway acts as the middleman: your instance initiates the connection, and the gateway handles the request and response, all without exposing your private instance to direct inbound traffic.
NAT Instances are considered a legacy approach, where you manually provision an EC2 instance to relay traffic between the private resource and the public internet – traffic flows from the protected resource to the NAT Instance and then out, with return traffic filtering in reverse. In much the same way that you typically wouldn’t want to launch and run a production database on a single EC2, NAT Gateways provide a managed, resilient service from AWS that is the NAT instance equivalent of RDS.
Aside: IPv6 addresses don’t have the concept of public/private IPs – there is a tool called an egress-only Internet Gateway which is used to provide the same type of functionality to resources with IPv6 addressing that NAT does for IPv4.
That is the super short, condensed breakdown of networking inside AWS. To give you an idea of depth, AWS has a specialty certification that specifically focuses on this topic and is considered one of the hardest certs to get. Properly configuring networking is one of the things that will make or break your entire cloud experience. There are a ton of other topics in this domain relating to security, monitoring, compliance, etc but if you walk away with a decent understanding of the topics I listed, you will have a solid foundation to dive in with.
Account/User Management
Account and user management is one of *the* most important topics in AWS. It’s not sexy, it’s often tedious, but not getting this right is what leads to account compromise and a nested mess of permissions that are attached to individual entities instead of roles.
“But wait,” you say, “how will I log in and manage my accounts?” Glad you asked.
Great question. You do it with IAM: AWS’s Identity and Access Management service. IAM lets you create users (individual people or systems) and roles (permission templates). These are managed via policies—documents that define what actions are allowed or denied.
One downside of creating users is the temptation to issue long-term access keys (used with tools like the AWS CLI). The problem is that those credentials stick around until manually revoked. If they leak, you might not know until damage is done.
A better approach is to use IAM Identity Center (SSO). This lets you manage a central user identity that can assume different roles across multiple accounts. Maybe that user has admin access in dev, but read-only access in prod. Plus, credentials are short-lived—they expire automatically, limiting blast radius.
Roles
Roles are like access badges you hand out to your team. Instead of configuring permissions one by one, you define what a role can do (like “BillingViewer” or “EC2Admin”) and assign it to whoever needs it.
You can also assign roles to resources, like giving an EC2 instance access to read from S3 or write logs to CloudWatch. These are called resource-linked roles.
Accounts
Accounts are the logical unit your AWS environment operates inside of. When you first sign up, you create an account, and by default, logging in with the credentials you used to set that up makes you the root user.
Guard your root user like your AWS bill depends on it — because it does. Anyone who gets access to your root user account has full, unfettered access to your AWS environment and can cause serious harm to your business and your bank account. Make this account very hard to access, and never ever let the credentials slip.
Here is an example – if a bad actor got control of your account with root-level access, they could turn your nice clean environment into a crypto farming monstrosity and stick you with the bill. That’s just one example, and it *does* happen in the wild from time to time due to misconfiguration or poorly secured account setup.
Unlike when signing up for most services online, you don’t have to do everything in that one account. AWS accounts can (and should) be used like project folders: logically isolated units you can spin up, shut down, or hand off as needed. It’s common to use different accounts for dev, prod, or billing separation.
Almost all modern cloud development uses Infrastructure as Code, which is a way to control what is in your account and how those things interact with a text file you can version control. You can take this file, and if done right, use it to launch a template you defined into ANY account.
A nifty trick for creating accounts without needing a new email for each one
Since AWS requires a unique email per account, instead of creating a new email each time you can use the +name trick – so if your root user account email is [email protected] and you want a production account you can use [email protected] – this doesn’t work for every provider but Gmail at least has no issue with this pattern.
So – let me lay it out
You create an account – and that makes you the root user. You secure the ever-living hell out of this account via 2FA (two-factor authentication), a strong password, etc. Then, you typically create a user in that account called something like “IAmAdmin” and give it Admin permissions via roles/policies.
This is the user you would normally use to do admin-level stuff. You also secure this user, but at least it can’t nuke the whole thing if access leaks (still would be very, very bad).
Then you set up SSO and create another user with the permissions needed in your account, and that is the account you use day to day.
When you use SSO, you get short-lived credentials that time out. If you have admin permissions, you can still use the CLI, but you have to validate your login periodically, so if somehow those credentials are compromised, they will automatically be revoked shortly after.
The reason you still need an admin user is, among other things, to be able to create new accounts and assign your SSO user to them. I am sure you can spot the issue if an SSO user, even an admin, could create and give themselves control over new accounts in your environment.
AWS Organizations.
Once you’re managing more than one account, you’ll want to look at AWS Organizations. Orgs allow you to group accounts into what are called OUs (organizational units) and in turn apply SCPs (service control policies) at the Org, OU, and individual account level to control what resources those accounts can and can’t provision.
There is also a service called Control Tower, which is like Orgs but on steroids and offers more automation and additional features that make it easy to manage hundreds of accounts in a single place. You may run into issues where a user or role might have permissions, but a SCP denies that action. If you run into weirdness like that, check the various levels of policy application
Lastly, I want to touch on a *critical* component of policies. AWS attempts to be as least permissive as possible by default – a user can’t do anything until you attach roles/policies to that user. A service cannot communicate with another service without a role. Scope your access as tight as possible – it might feel overly restrictive at first, but it can save you serious pain in the long run.
Something to take note of – the order of operations on a policy for IAM is Deny, Allow, Deny. By default, everything is denied. You can log in, but that’s it. Nothing will be accessible to you. After Deny, comes *explicit allow* – these are things you code into the policies to allow specific actions on specific resources. You can be a mad lad and use * when doing that, but it is bad practice to do so. While a pain, make sure you only give exactly the access required. Finally is Deny again – if it is not implicitly denied (the first Deny), you can SPECIFICALLY deny access to resources. This will OVERWRITE an allow. Below are two examples of (simple) policies you might encounter:
1. Read-Only Access to a Specific S3 Bucket

my-company-logs, but denies the ability to write, delete, or touch any other bucket in that account.2. EC2 Start/Stop/Describe Across All Instances (but no create/delete)
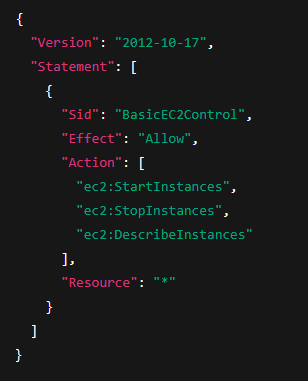
Resource: "*" is used here because EC2 actions often require wildcard resources unless specifically scopedRemember: Deny, Allow, Deny.
The order of IAM policies generally does not matter in AWS. All applicable policies are evaluated, and an explicit deny statement always takes precedence over an allow statement. The outcome is either allow or deny, regardless of the order of the policy statements. If you’re troubleshooting access issues, AWS offers a policy simulator to test what a user or role can actually do/access with a given policy. This can get incredibly complicated in larger accounts, I highly advise you to look at this article, which goes into much greater detail about policy evaluation.
I usually avoid saying “just follow best practices,” but here’s one you absolutely should follow: Least Privilege Access.
Let’s use a metaphor: Imagine your AWS account is an office building. Somewhere inside is a locked server room (your sensitive resources). You also have janitors (users). They have a role that lets them enter and leave the building and access the supply closet. They need to clean the offices, but do they need to access the server room? Even if they’re harmless, the risk isn’t worth it. Least privilege means giving people only the access they actually need. Maybe your janitors are harmless, and even if you did let them enter that room, it would be fine. Maybe a competitor gets access to a janitor who has access to your assets… that would be a problem.
IAM Recap:
- Lock down the root account
- Use roles, not inline permissions
- Prefer SSO + short-lived credentials
- Use IAM policies carefully: Deny → Allow → Deny
- If it feels messy, it probably is — stop and fix it early
Again, I really cannot stress enough how important getting this piece right is to the health and security of your account(s).
Alright, enough theory. Let’s look at some actual services.
Services – common cloud offerings and when to use them
Below are a series of commonly used services you can consider foundational building blocks in AWS. I have split this into a couple of different sections: Compute, Storage, Database, Security/Logging/Encryption, and Serverless. We already touched on networking and account services above so these are meant to cover a handful of core tools you can use in AWS to build… well, almost anything. I am leaving out a *lot* of detail and naunce, and there are dozens of more services for you to find and learn about, but this list should get you started.
Compute
Compute services are one of the most fundamental offerings from any cloud provider. In short, they let you provision and run — well — compute. It’s on-demand processing power you can scale up or down as needed.AWS offers several core compute options, depending on how much control (or lack of control) you want.
When it comes to compute – pricing models, cost optimization, security, instance types, auto-scaling, licensing, and a dozen other rabbit holes we could explore are all important things to consider, but they are out of scope for this introduction.
EC2

EC2 (Elastic Compute Service) lets you provision, scale, and manage virtual machines (VMs) in AWS. You pick your operating system, define how much RAM/CPU you need, and AWS gives you a VM that you can SSH into and treat like any other server. You’re responsible for managing the instance — patching, installing software, securing it, etc.
EC2 instances run inside specific subnets in your VPC, and you can scale them horizontally (more VMs) or vertically (bigger VMs).
EC2s come in a wide variety of sizes, from a tiny VM that may as well be an older gen Raspberry Pi to an absolute monstrosity of a machine with over a terabyte of vRAM.
EC2s has a couple of subtypes/ways to provision – these are (in brief)
On Demand – The most typical way to provision EC2. You pay for what you use, and can shut them off at any point/spin up new ones as your demand grows (or spikes). These are billed hourly, but you are guaranteed access to them while they are running (barring issues at the physical location). Great for when you need to scale flexibly, but have workloads that cannot handle being interrupted.
Spot – Spot instances are AWS’s way of trying to make sure as much capacity as possible is being rented by users. Just like the cloud solved an overprovisioned server wasting resources on-prem, having idle EC2 capacity is just burning money for them. So, spot instances. These are also billed hourly, but at a fraction of the on-demand price. So what’s the catch? At any moment and without warning, AWS can yank that capacity back for other users who either need it or are willing to pay more for it. You get a two-minute warning, and then are ejected (so to speak) – these are great for short-lived workloads where interruption is accounted for and play very nicely with many of the types of things you would put in a queue (see SQS further down).
Reserved – If you know in advance how much compute you need, reserved instances allow you to pay a reduced cost upfront to well, reserve capacity. The downside here is you are locked in, so if you end up not needing the resources, you are still stuck paying for them
EC2 could be a 10k-word post by itself, but that should be enough info to give you an idea of what it is and some options you can consider
If you need to provision a VM inside AWS, EC2 is the service you want to use.
ECS

ECS (Elastic Container Service) helps you run and manage containerized workloads on top of EC2. It handles deployment, scaling, health checks, and more, while still giving you full control of the underlying EC2 infrastructure.
Need to run containers on your EC2? ECS.
Fargate

Fargate is like ECS, but you don’t have to manage the EC2 instances underneath. You just say, “Here’s my container, and here’s how much CPU/RAM it needs,” and AWS handles the rest. This makes it a serverless container platform — kind of a midpoint between EC2 and Lambda.
Need to run containers but don’t want to touch EC2? Fargate.
EKS

EKS (Elastic Kubernetes Service) is AWS’s managed Kubernetes offering. If your team is already using K8s — or you’re migrating a K8s workload — EKS gives you the control plane (the brain of a Kubernetes cluster) and automates a lot of the heavy lifting.
Need to run Kubernetes clusters on AWS and want AWS to manage the control plane? EKS.
Auto Scaling Groups and Elastic Load Balancing
You can’t really talk about compute in AWS without mentioning ASGs and ALBs. I’ll keep this You can’t talk about compute in AWS without mentioning ASGs and ALBs. I’ll keep this short, but just know: in any real production environment using EC2, Fargate, etc. (EKS has its scaling methods), both of these are used extensively.
- Auto Scaling Groups (ASGs) let you say, “Based on some criteria, scale up to X number of instances, and then back down when demand drops.”
- Application Load Balancers (ALBs) sit on top (usually) of ASGs and evenly distribute incoming traffic so no single VM gets overwhelmed.
Elastic Load Balancers (ELBs) come in two main flavors:
- NLB – Network Load Balancer (Layer 4: TCP/UDP). Use this when you need speed, low latency, or to handle protocols outside HTTP.
- ALB – Application Load Balancer (Layer 7: HTTP/S). Use this for web apps, APIs, etc.
ASGs help your compute scale. ALBs/NLBs help your traffic scale.
Storage
Storage is another piece of the cloud puzzle. AWS offers several different types of storage depending on what kind of data you’re storing, how fast you need to access it, and how long you want to keep it around.
Some storage is optimized for high-speed access, some is meant for massive scale, and some is built for long-term archival at the lowest possible price.
Like compute, storage has a ton of nuance — durability guarantees, pricing tiers, lifecycle policies, access patterns, etc.
Here are some of the core storage offerings from AWS, and when to use them:
S3

S3 (Simple Storage Service) is the AWS offering for object storage. It provides cheap, scalable, durable, and secure storage for objects.
An object, in this context, is simply a file plus some metadata. It could be anything — a .jpg, a PDF, a .zip file, a backup, a video — and it gets stored in what AWS calls a “bucket.”
You don’t think about directories or mounting anything; you just toss your object in, and AWS gives you a key (a path) to retrieve it later.
You can also host and serve entire websites from inside of S3 – very useful for static sites.
S3 includes options for security, compliance, auditing, automation, and various storage classes. I’m going to touch on a few common storage classes here because they’re important, and they can drastically impact your costs.
- S3 Standard – For frequently accessed data
- S3 Infrequent Access – For data that requires rapid access but is accessed less frequently
- S3 Glacier – For long-term, durable data archival at the lowest possible *storage* cost (think backups, compliance data, old logs, etc.)
S3 supports various ways to secure your data at rest, options for regulatory compliance, and other great features like versioning and cross-region replication for additional resiliency.
S3 is the go-to service for storing objects such as media and other static content in a durable, secure, scalable, and resilient manner inside AWS.
EBS

EBS (Elastic Block Store) is pretty easy to conceptualize — if EC2 is a VM you provision in the cloud, then EBS is the virtual hard drive you attach to that VM.
In some cases, one EBS can be attached to multiple EC2s to allow shared storage. However, typically, EBS is provisioned and attached to a specific instance.
EBS is one of those single-AZ type things I mentioned earlier. If you provision an EBS volume in a specific Availability Zone and that AZ gets hit with a laser from orbit, you’ll lose the volume and any data on it. Fortunately, AWS gives you options for snapshots and replication to reduce that risk.
EBS volumes come in two main flavors:
- SSD-backed (General Purpose and Provisioned IOPS) – great for most apps
- HDD-backed – slower, but useful for certain high-throughput workloads
SSD-backed volumes are faster and more commonly used, while HDD-backed volumes are backed by traditional spinning disks. They’re not ideal for most apps, but can be cost-effective for specific scenarios.
You can read more about volume types here.
Use EBS when you need persistent block-level storage for EC2 — it’s your VM’s hard drive in the cloud.
EFS

EFS (Elastic File Store) is an AWS-managed service that lets you provision a POSIX-compatible file system inside AWS. EC2 instances can connect to that file system at boot (or later), giving each instance access to — well — a shared file system.
EFS does not support Windows-based workloads. If you need a shared file system for Windows instances, AWS offers a separate managed service called FSx for Windows File Server — I’ll touch on that later.
Need a shared linux compatible file system inside AWS? EFS is the go-to.
FSx for ONTAP/OPENZFS/LUSTRE/WINDOWS

FSx is a family of high-performance managed file systems. If EFS is a normal file store, the FSx offerings are like EFS Turbo Plus Ultra.
There are currently four supported FSx types:
- FSx for NetApp ONTAP
- FSx for OPENZFS
- FSx for Lustre
- FSx for Windows.
I can really only speak to FSx for Lustre and FSx for Windows, so I’ll keep it brief:
FSx for Lustre is the “Turbo Plus Ultra” version of EFS and is typically used for high-performance computing. It is used with GPU-focused instances and is often seen when training machine learning workloads, processing huge data sets, and when super-low latency data access is required.
FSx for Windows is a fully managed, Windows-native file share that integrates with Active Directory and other Windows-based tools.
It is unlikely that when starting your cloud journey, you will need any of the FSx products, but they do exist.
Database Services
RDS

RDS is another one of those foundational services. It allows you to provision a relational database in a variety of flavors — MySQL, PostgreSQL, MariaDB, SQL Server, Oracle, etc. — without needing to worry about the underlying compute, patching, or other overhead typically associated with managing a database engine.
RDS includes built-in tools for high availability, scalability, disaster recovery, performance tuning, security, and pretty much everything else you’d expect from a production-grade database service.
While you do launch your RDS instance (or cluster, depending on setup) into subnets inside your own VPC, you don’t actually get access to the EC2 the databases are running on. Instead, you are given an endpoint and use that to connect to your database of choice – from there, treating it like any other database you might have traditionally installed yourself.
While you 100% can install a database directly on EC2 — and in some cases, still need to (due to licensing restrictions or unsupported database engines) — doing so puts the onus on you to make sure your DB is secure and up to date, and also has the downside of tying the DB to a single EC2. Virtual Machines *do* crash, and when they do, they will take your DB with them. RDS allows you to decouple your database tier from your compute tier and scale it independently without requiring a full team of DBAs on staff.
Reach for RDS when you need a relational database in the cloud but don’t want to manage the underlying infrastructure yourself — it’s reliable, scalable, and can help takes care of backups, failover, and patching so you don’t have to.
Aurora

Technically, Aurora falls under the RDS family of products… but not really.
What I mean by that is: Aurora is a MySQL- and PostgreSQL-compatible database engine built by AWS, specifically for the cloud. It behaves like RDS, and you interact with it through the same tooling — but it’s not just a regular MySQL or Postgres instance under the hood.
Aurora is designed to be extremely performant, highly available by default, and resilient at scale. It replicates your data across multiple Availability Zones, can auto-heal, and handles failover in seconds, much faster than traditional RDS.
You do pay a bit more for Aurora compared to standard RDS, but depending on your needs, that tradeoff might make sense.
If you need a managed relational database and are expecting high traffic or want something designed specifically for scale in the cloud, Aurora is worth a look.
DynamoDB

DynamoDB is a cloud native NoSQL database service provided by AWS. Unlike traditional RDS offerings, really what you are provisioning is a table that supports a flexible structure and scales incredibly well while providing insanely low latency (single digit in some cases) and offering a pay for what you use model.
Dynamo has some nifty features, like Streams, which allow you to trigger additional logic or flows based on inserts, DAX, which provides even better performance by adding a caching layer, and the ability to have global tables to handle DR along with point-in-time recovery options (PITR).
The free tier for DynamoDB is pretty generous, though I think the way they calculate pricing is not super intuitive. DynamoDB uses something called WRU (Write Request Units) and RRU (Read Request Units) (previously know as WCU and RCU) – even with that, it can still be insanely cost-effective even at some scale.
When I say counter-intuitive, I mean that you provision a number of WRUs and RRUs, but the pricing isn’t linear — for example, a single RRU gives you 1 million read requests for just $0.125. Cheap, but not exactly obvious. Pricing in AWS isn’t always sane.
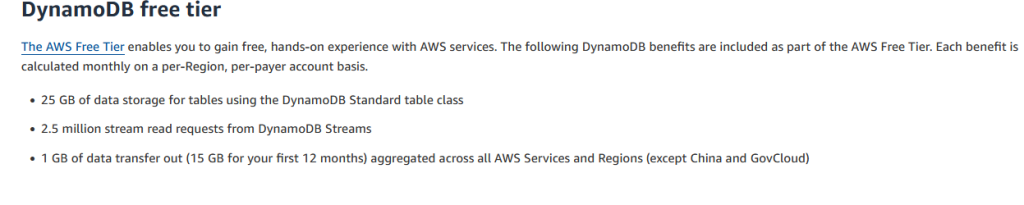
DynamoDB is a great option if you want a performant, scalable, cloud-native NoSQL database without needing to manage underlying infrastructure. It integrates cleanly with serverless architectures, and it’s not an “either/or” with RDS — many apps use both depending on the data model. Use the right tool for the job.
Neptune, DocumentDB, Timestream, Redshift, etc – There are other database services AWS offers that you generally won’t need unless you already know why you need them – but I am listing a couple of them so you are aware they exist for those specific use cases that require them.
- Neptune – The AWS offering for a managed graph database.
- DocumentDB – A NoSQL database that’s specifically MongoDB-compatible.
- Timestream – A fully managed, serverless time series database, optimized for ingesting and querying time-stamped data.
- Redshift – A managed, petabyte-scale data warehouse designed for big data analytics and OLAP (online analytical processing). Ideal for querying massive datasets using SQL.
These and a handful of other make up a selection of much more niche products, but they do exist and are worth being aware of in the periphery.
Security, Encryption, and Logging
Security, encryption, and logging services are crucial for making sure no bad actors have access to your resources while providing ways to log what is happening inside your account in a way that is centralized and auditable.
Some topics I would consider security are not really about the actual managed options inside AWS, but about general account hygiene – like making sure 2FA is enabled, making sure your policies follow the least permissive approach, and requiring all access to be short-lived via STS and role assumption.
However, even if you do all of that, there is no guarantee the doors are actually locked as tightly as they need to be. Like everything else, you have to strike the right balance of paranoia and practicality for what *you* are doing. A static site sitting in S3 probably doesn’t need you to enable Guard Duty.
All that being said, AWS *does* offer a robust selection of tools and services for logging, monitoring, encrypting, and securing both content and resources – the ones you will encounter day to day or should be aware of are as follows:
CloudWatch

CloudWatch is a centralized logging service that allows you to create CloudWatch Trails to log what is happening with resources inside your account. What calls are being made, what machines are doing what, etc. It also provides the ability to set alarms (such as billing alarms – which you 100% should do) and the ability to track resource utilization on EC2 to trigger scaling and other events.
There is a ton of depth to CloudWatch, and it deserves (and will hopefully be getting) its own dedicated post – but you should be comfortable at least navigating this service at a high level. A piece of advice – create a billing alarm with CloudWatch the moment you spin up an account — it could save you hundreds and a huge headache down the road.
CloudWatch is where you will go to monitor, set alarms, and help debug calls to your resources.
CloudTrail

If CloudWatch is the “what”, CloudTrail is the “who” – CloudTrail allows you to make trails that track access to resources. Who enabled a setting on a resource. What user accessed a given service, etc. Who accessed your API and when. It provides a way to track and log account activity and your day-to-day operations – very useful for compliance and auditing. CloudTrail stores its logs in S3 and optionally pipes into CloudWatch Logs.
CloudTrail supports the ability to consolidate logs across multiple accounts in your organization, and also provides the ability to help analyze management events on your behalf to help spot suspicious access patterns as they occur
CloudTrail tracks who did what, when, and from where across your account — like who accessed which service, changed a setting, or called your API (and with what credentials).
AWS GuardDuty

AWS GuardDuty is a service that continually monitors your account and environment for suspicious activity – using ML/AI to detect threats and unusual access patterns – for personal and hobby accounts it is probably overkill assuming you set up your IAM correctly, but it is a core security service and worth talking about.
Your account is like a gated community, GuardDuty is like a private security guy you hired to drive around in a golf cart and look out for shady characters or suspicious vehicles.
AWS Inspector

AWS Inspector is another automated security service, but instead of operating at the account level, it operates at the resource level. Inspector scans things like your EC2s to automatically detect software vulnerabilities, assess areas that could be exploited, help automate remediation, and help manage various compliance requirements.
If GuardDuty is the guy you hired to protect your gated community, Inspector is like having someone in each of your houses making sure doors are locked and that the windows can’t simply be opened, while also making sure people who are not supposed to be inside aren’t and that nobody tried to sneak in through said windows.
WAF

AWS WAF (Web Application Firewall) is a firewall service provided by AWS that helps filter out common web exploits, such as sql injection attempts, while also providing features like rate limiting to help prevent bad actors and bots from overloading your resources or making calls that might cause issues across your account. You create what is called a Web Access Control List (WACL) and then create rules associated with that WACL – such as “block any IPs that try to hit this endpoint more than 5x/second.
WAF is not free, but it is relatively low-cost for what it provides. WAF integrates directly with both CloudFront and Elastic Load Balancer, among others, and you can assign the same WACL to multiple resources. Each resource can only have one WACL, however. It also offers some more advanced bot control and captcha verification stuff, but those come with an extra cost.
AWS Shield

AWS Shield is a service designed to detect and prevent DDoS attacks against your account and the resources inside of it. Shield comes in two flavors – standard and advanced. Standard is provided free of charge to every account and provides transport layer protection against common DDoS attacks. Shield Advanced is an optional, fairly expensive version of this product that offers advanced enhancement and mitigation features.
You can compare the two HERE – just note that Shield Advanced comes with a whopping *$3,000/mo* price tag with a minimum one-year commitment. Do *not* turn this on unless you have a reason to.

KMS

KMS (Key Management Service) is a super important service to be aware of. KMS allows you to provision and manage cryptographic keys which you then use to encrypt your data. KMS integrates with many of AWS’s products, and is a critical service to securing your data in the cloud.
KMS offers three types of keys – Customer managed, AWS managed, and AWS owned.
Customer-managed keys are ones you (the customer) create and control. AWS managed keys are ones AWS creates and manages on your behalf (For example, S3-SSE can use these if you don’t want to have to think about HOW the keys are created/linked). AWS-owned keys are created by AWS and used internally for encryption between AWS services – you never see these.
Need to provision encryption keys for use in AWS? KMS.
System Manager Parameter Store

SMPS is a service that allows you to store values in a parameterized way for access by other applications and services. Simply put, you can define enviroment variables here and those can be used (for example) when launching an EC2 instance.
You can also store *sensitive* information using the secure string type – this will encrypt the value (via KMS) and could be used for something like a secret header value or an RDS username/password. It’s free unless you use some of the more advanced features, and if you are familiar with GitHub works similarly to secrets in a repository.
Secrets Manager

Like SMPS, Secrets Manager allows you to secure your secrets in a durable, encrypted manner. Unlike SMPS, it isn’t free. However, it does do something SMPS does not, and that is automatic rotation of secrets.
Be it best practice or for compliance reasons, sometimes you need (or want) to rotate things like database credentials. Secrets Manager can do this for you, and then automatically sync the new secrets to the services that are using it (like RDS).
If you’re storing config values, secrets, or credentials, consider whether they need rotation (Secrets Manager) or just secure access (SMPS). Either way, KMS is doing the encryption under the hood for both.
Here is a quick guide to the services discussed for easy, top-of-mind access
- CloudWatch => “what did what”
- CloudTrail => “who did what”
- GuardDuty => threat monitoring
- Inspector => vulnerability scanning
- WAF => request filtering
- Shield => DDoS protection
- KMS => Create and manage encryption keys
- SMPS => Store encrypted config values (env vars, secrets, etc)
- Secrets Manager => Store secrets with encryption + automatic rotation
Other Security & Compliance Services
If you’re working in a more regulated environment or building for production at scale, there are additional tools worth knowing about:
- Security Hub – a centralized dashboard that pulls in findings from GuardDuty, Inspector, IAM Access Analyzer, and others. Good for org-level visibility.
- Macie – scans your S3 buckets for sensitive data like PII or credentials, and helps with compliance audits.
- AWS Config – lets you track infrastructure drift and ensures your environment stays in a compliant state.
- IAM Access Analyzer – shows you which resources (like buckets or roles) are shared with other AWS accounts or made public.
- Audit Manager – helps with automated evidence collection for compliance frameworks like SOC 2 or HIPAA.
Serverless
Serverless services are those that allow you to simply interact with the resource without having to worry about underlying infrastructure or compute. With serverless, you shift more of the underlying responsibilities to AWS. Serverless development architecture can be a full-time job in and of itself. We have touched on a few of these already, like DynamoDB and SQS. Below are some of the additional common offerings you will encounter inside AWS and when/why you may wish use them.
Lambda

Lambda is one of the core serverless offerings in AWS. It is commonly used to create APIs or run automation/remediation on other resources in your account. You might create a Lambda that triggers when an S3 PUT event is detected, doing something with whatever object was just added to your bucket. You may use it as a way to allow access to Dynamo or other services via POST/GET requests. Lambda is a great example of how serverless shifts the overhead to AWS – at the end of the day, it’s still using compute under the hood – but for you, you are simply writing code that will run and are not required to think about the environment or underlying complexity to make that happen.
Lambda supports most common languages (JS, Python, C#, Java, Go, etc) as well as the ability to run certain types of containers directly from Lambda. It is often used to build efficient, cost-effective systems for web-based applications, interact with ML/AI services, or handle things like data processing.
Lambdas are a core piece of the AWS ecosystem and provide an insane amount of flexibility; however, there are a few things to be aware of:
- Lambdas are not meant for long-running processes – if your request to Lambda takes more than 15 minutes, it will time out and the request will fail.
- Lambdas can hit concurrency issues and, in turn, be throttled if not configured correctly
- It is possible to create infinite lambda loops, which are a great way to flash fry your finances. For example, a Lambda that triggers on S3 PUT, which in turn does a PUT to that same bucket. I’m not kidding. Don’t do this.
- Cold Starts – some lambdas may have a bit of initial time to spin up before they process the request – like I mentioned, they ARE still running on top of compute, it’s just abstracted away
You can think about Lambda almost like a scripting service inside AWS that can run its own logic as well as interact with other AWS services in a cost-effective, scalable, and performant way.
API Gateway

API Gateway is a fully managed service that lets you create, publish, and manage APIs. You define your routes, configure integrations (like Lambda, HTTP backends, or mock responses), deploy to a stage, and then expose that API for external use.
It’s tightly integrated with a bunch of AWS features — like IAM-based auth, JWT/OIDC auth, API key usage plans, rate limiting, caching, throttling, logging, and WAF integration. It’s a strong candidate any time you need a well-structured way to expose AWS-based services or connect external consumers to internal AWS logic.
AWS offers three types of APIs via API Gateway:
HTTP APIs – These are lightweight, cheaper, and faster to set up. They’re ideal for basic use cases where you don’t need all the bells and whistles. These are often used to front a Lambda function or simple backend service. Downsides? You lose access to some advanced features like caching, WAF integration, and fine-grained request/response transformations.
REST APIs – If you need things like usage plans, stage-level throttling, request validation, API Gateway-authorizers (like Cognito), or more complex routing/customization, REST APIs are the move. They cost more than HTTP APIs but offer more control.
Websocket APIs – These are a different beast entirely. Used for building real-time, bidirectional communication (think chat apps, multiplayer games, live dashboards, etc.). They require you to handle connection state yourself, which adds complexity, but they’re powerful for interactive use cases.
AWS has a solid guide on choosing between HTTP and REST APIs — check it out if you’re unsure which to start with.
Example: Serverless API Flow – A user request hits API Gateway, which routes it to different Lambda functions depending on the path or method. Each Lambda then performs an action: querying a database (top), accessing an S3 bucket (middle), or interacting with another AWS service (bottom).”
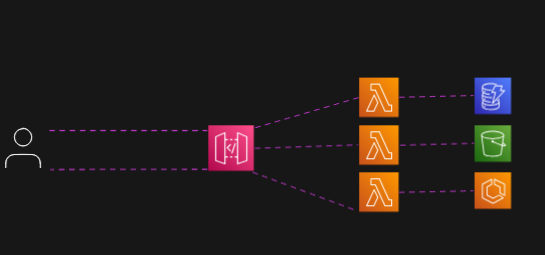
Anytime you need to create an API for external resources to consume and your functionality is backed by Lambda, API Gateway is a must-have tool in your arsenal.
Step Functions

Step Functions provide a way to visually (or with code) create a series of steps for serverless and other workflows. They’re also a way around the 15-minute time limit for Lambda, since you can break long-running tasks into smaller steps and coordinate them.
They typically operate in a “do this, then do that, then depending on the result, do A or B” fashion — but they can get pretty complex quickly. One of their biggest strengths is that they can manage and track state (something Lambda doesn’t natively do) and pass data between steps in a structured, visual way.
You define Step Functions as state machines, which is beyond the scope of this post, but something you can read up on more (and I suggest you do so).
Step Functions are a great tool for orchestrating and managing complex, multi-step workloads in a scalable, managed, and resilient way — especially when you’re tying together services like Lambda, SQS, SNS, or DynamoDB.
SQS

SQS – (Simple Queue Service) was the very first service AWS launched as a public product. Like the name implies, it provides a Queue as a Service option to your workflow. SQS is one of the most important services when it comes to decoupling applications and can be used to scale up and down EC2s based on the number of requests in a given queue. SQS comes in two flavors, Standard and FIFO.
Standard Queues provide nearly unlimited throughput, best-effort ordering, and at-least-once delivery. Great for general use and high-volume workflows. You might use this queue type to queue up orders for processing for an e-commerce site, or to help handle a voting app for a popular TV show (think voting for America’s Got Talent or similar), or to queue up credit card purchases for validation.
FIFO Queues guarantee order and exactly-once processing, but with lower throughput. Perfect for workflows that require strict sequencing (like financial transactions or ordered messaging systems). Think of an online ticketing platform where access to purchase tickets is distributed on a first-come/first-serve basis.
SQS should be your go-to when you need to decouple your application layer from the data it is receiving, or when you need a reliable, scalable “queue-as-a-service” inside AWS.
SNS

SNS (Simple Notification Service) is a fully managed service that makes it easy to publish messages from one service and then fan out those messages to one or more subscribers. It’s Pub/Sub as a service, in AWS. Publishers send messages to a Topic (this is something you set up), and then you set other resources to listen for notifications to that topic.
Honestly, the official diagram from the SNS docs on AWS provides a great visual example, so I will simply put that here:
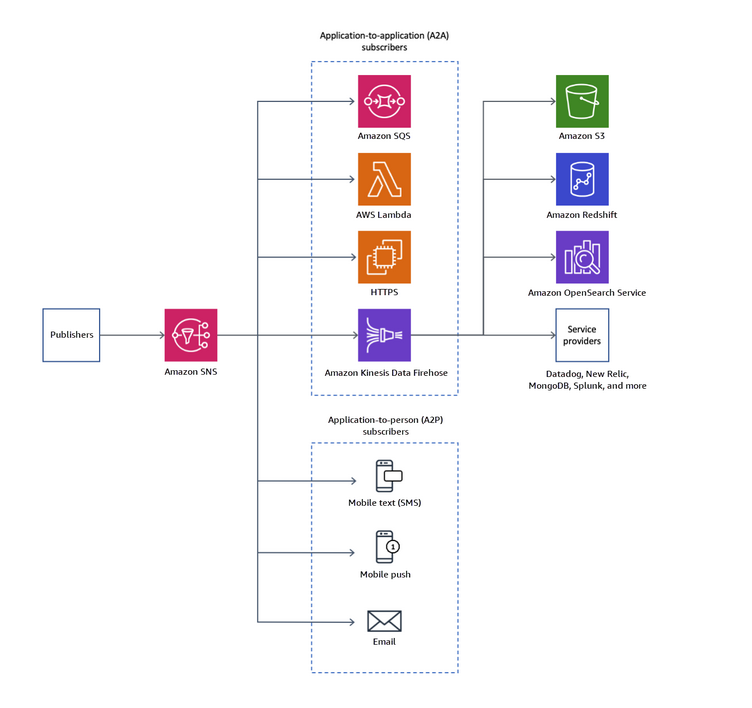
Reach for SNS if you need a fast, scalable service that provides Pub/Sub functionality and supports fan-out architectures.
There are several other serverless services I have not mentioned, but the ones above represent a solid conceptual foundation. Most of the other offerings in this category are either more specialized or relate to working with various ML/AI products, such as Bedrock, Rekognition, etc.
Summary
Well, that’s it – that’s a basic overview of the core services and concepts you need to get started with AWS. I glossed over a *lot* of detail, even with this post being as long as it is. Like I mentioned near the start, I also neglected to mention a ton of other services, tools, and considerations for building and deploying into the cloud. However, this should hopefully provide you with a foundation you can use going forward, so when you encounter these topics and services at work or want a reference point for diving in, you have one.
Thanks for reading. See you next time.